Architecture
Siren Federate is designed around the following core requirements:
-
Low latency, real time interactive response – Siren Federate is designed to power ad hoc interactive, read only queries such as those sent from Siren Investigate.
-
Implementation of a fully featured relational algebra, capable of being extended for advanced join conditions, operations and statistical optimizations.
-
Flexible in-memory distributed computational framework.
-
Horizontal scaling of fully distributed operations, leveraging all the available nodes in the cluster.
-
Federated – capable of working on data that is not inside the cluster, for example via JDBC connections.
Siren Federate is based on the following high level architecture concepts:
-
A coordinator node which is in charge of the query parsing, query planning and query execution. We are leveraging the Apache Calcite engine to create a logical plan of the query, optimise the logical plan and execute a physical plan.
-
A set of worker processes that are in charge of executing the physical operations. Depending on the type of physical operation, a worker process is spawned on a per node or per shard basis.
-
An in-memory distributed file system that is used by the worker nodes to exchange data, with a compact columnar data representation optimized for analytical data processing, zero copy and zero data serialisation.
Distributed Join Workflow
When sending a (multi) search request with one or more nested joins, the node receiving the request
will become the “Coordinator”. The coordinator node is in charge of controlling and executing a “Job” across the
available nodes in the cluster. A job represents the full workflow of the execution of a (multi) search request.
A job is composed of one or more “Tasks”. A task represent a single type of operations, such as a Search/Project
or Join, that is executed by a “Worker” on a node. A worker is a thread that will perform a task and report the
outcome of the task to the coordinator.
For example, the following search request joining the index companies with articles:
GET /_siren/companies/search
{
"query" : {
"join" : {
"type": "HASH_JOIN",
"indices" : ["articles"],
"on": ["id", "mentions"],
"request" : {
"query" : {
"match_all": {}
}
}
}
}
}will produce the following workflow:
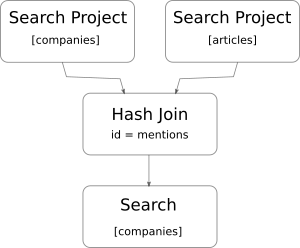
The coordinator will execute a Search/Project task on every shard of the companies and articles indices.
These tasks will first execute a search query to compute the matching documents, then scan the id and mentions
fields of the matching documents and shuffle them to all the nodes of the cluster. Once these tasks are completed,
the coordinator will execute a Hash Join task on every node of the cluster. The Hash Join task will join the
two streams of data that were sent by the two previous Search/Project tasks to compute a set of document ids
for the companies index. These documents ids will be transferred back to their respective shards and used to
filter the companies index.
This particular workflow enables Federate to push all the filtering predicates (e.g., terms, range, boolean
queries) down to Elasticsearch, leveraging the indices for fast computation. The Join task is currently limited
to compute the intersection of two different set of documents based on a join condition. This reduces the amount of
data allocated in memory, the amount of data transferred across the network, and the workload performed by a task.
Query Planning & Optimisation
The coordinator node is leveraging Apache Calcite for planning the job execution. A search request is first parsed into an abstract syntax tree before being transformed into a logical relational plan. A set of rules will then be applied to optimise the logical plan. We leverage both the Hep and Volcano engine to optimise the logical plan using heuristic and statistical information. The logical plan is then transformed into a physical plan before being executed.
The physical plan represents a tree of tasks to be executed. The coordinator will try to execute tasks concurrently
when possible. In the previous example, the two Search/Project tasks are executed concurrently, and the
Hash Join task is executed only after the completion of the two Search/Project tasks.
When handling a multi search request, each request will be planned separately, each one producing a physical plan. However, before the execution of the physical plans, the planner will combine all the physical plans into a single one, by mapping identical operations to one single task. We can see that as a step to fold multiple trees of tasks into a single directed graph model, where overlapping operations across trees will become one single vertex in the graph. This is useful to reuse computation across multiple requests.
IO
The shuffling and transfer of data produced by a task is handled by a Collector. A collector will collect data,
serialize it into a compact columnar data representation, and transfer it in the form of binary packets.
Different collector strategies are implemented that are adapted to different tasks. For example, in case of a
Hash Join, a Search/Project task will use a collector with a hash partitioning strategy to create small data
partitions and shuffle these partitions uniformly across the cluster.
On the receiver side, when a packet is received, it is stored as is (without deserialization) in an in-memory data
store. Tasks, such as the Join task, will directly work on top of these binary data packets in order to avoid
unnecessary data copy and deserialization.
The binary data packets are created, stored and manipulated off-heap. This helps to reduce unnecessary loads on the JVM and Garbage Collection when dealing with a large amount of data. We are leveraging the Apache Arrow project for the allocation and management of off-heap byte arrays.