High Availability (HA) for node clusters
Siren Alert supports High Availability (HA) for reporting on node clusters. This provides continued service of the alerting system when a cluster’s master node fails, by switching the master’s responsibilities to another node. The reporting functionality is muted on all but the master node, preventing duplicate reports being sent for each alert.
Functional overview
In a cluster, there is only one master node—all other nodes are slaves. If the master is down, the first slave that detects this is elected the new master.
Time is taken into account to define master and slave statuses, and identify dead nodes; this time is represented as the number of seconds since Unix Epoch. The master has priority (priority_for_master) and all slaves watch the current master with a specific timeout (loop_delay). If the master does not update its time within the specified period of time (absent_time), it is considered offline, and an election of a new master takes place. All nodes which are absent for a specified period of time (absent_time_for_delete) are considered dead and are deleted from memory.
Siren Alert cluster setup
Cluster configuration with High Availability
sentinl:
settings:
cluster: # configuration for the cluster
enabled: boolean # enable / disable the cluster configuration (false by default)
debug: boolean # debug output in the Investigate console (false by default)
name: string # name of the cluster configuration
priority_for_master: number # master's node priority (0 by default)
absent_time_for_delete: number # how long before a node is removed from the cluster (86400 sec by default)
absent_time: number # how long the slaves wait for a response from the master before electing a new master (15 sec by default)
loop_delay: number # how long between polls from slave to master (15 sec by default)
cert: # configuration for security's certificate
selfsigned: boolean # if certificate is self-assigned (true by default)
valid: number # validation of certificate (10 by default)
key: string | null # path to key (undefined by default)
cert: string | null # path to certificate (undefined by default)
gun: # configuration for each gun db host
port: number # unique for each gun db host
host: string # gun db host
cache: string # path to gun db cache file
peers: string[] # contain urls to all gun db instances including this one
host: # host's configuration
id: string # must be a unique ID
name: string # name of elasticsearch node
priority: number # priority 0 = master, priority 1+ = slave
node: string # name of node within gun DB - all gun db instance configurations in HA cluster must share same node name
Example of configuration
The following cluster topology is an example of HA configuration:
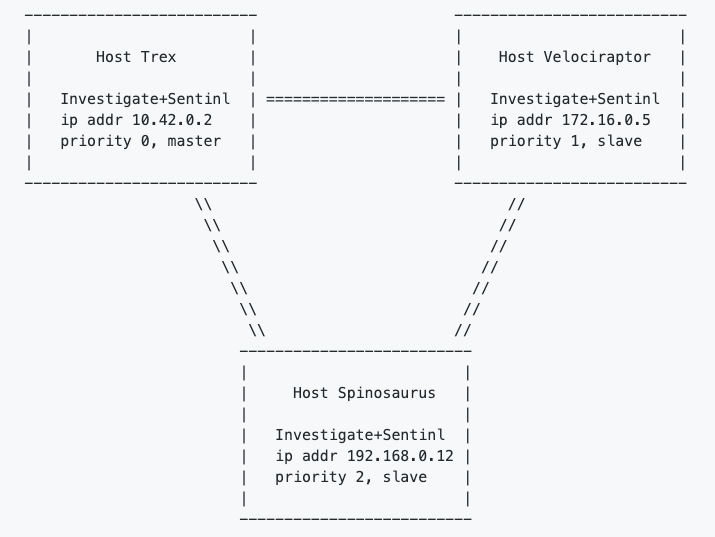
In the following configuration examples, the ellipsis (…) indicates that the options here are identical to the options specified in the example above.
elasticsearch.yml
Host Trex
cluster.name: kibi-distribution network.host: [_local_, _enp2s0_] discovery.zen.minimum_master_nodes: 2 node.name: trex discovery.zen.ping.unicast.hosts: ["172.126.0.5", "192.168.0.12"]
investigate.yml
Host Trex
sentinl:
settings:
cluster:
enabled: true
name: 'sentinl'
priority_for_master: 0
absent_time_for_delete: 86400
absent_time: 15
loop_delay: 5
cert:
selfsigned: true
valid: 10
gun:
port: 9000
host: '0.0.0.0'
cache: 'data.json'
peers: ['https://localhost:9000/gun', 'https://172.16.0.5:9000/gun', 'https://192.168.0.12:9000/gun']
host:
id: '123'
name: 'trex'
priority: 0
node: 'hosts'