Editing entity tables
In the Data model app, all entity tables are listed in a list to the left of the screen.
When an entity table is viewed in the Data model app, its settings are divided into several tabs. These tabs are where you can edit an entity table’s structure, view its data, and update its configuration options.
You can perform the following tasks:
-
Modify the basic information about the entity table, such as its name, icon, color, and description.
-
Modify and organize the fields in the entity table.
-
Modify the data in the records, add filters, create searches, and generate dashboards.
-
Add relations between entities in the data.
-
Create and modify scripted fields.
-
Configure options that can maintain system performance when processing large amounts of data.
-
Manage associated template scripts to customize the view mode on the Record view.
-
Configure record editing to store revisions of the data.
-
Configure the options for searching data and boosting fields in the Global Search interface.
-
View the entities and their relations in a graphical visualization.
The Info tab
On the Info tab, you can modify the basic information about the entity table, such as the name, icon, and color.
You can also set the following properties:
-
Default label: You can compose the label that is used for the records when they are viewed in the Graph Browser, the record view, or in global search results. This can be either a Scripted Label or a Document Field. If you are using a scripted label, you must use a specific syntax to display the label. For example,
@doc[_source][title]@displays the contents of thetitlefield as the label. -
Default image: In a similar way to the default label, you can specify an image that displays for the entity table, either by using a Scripted Label or a Document Field. If you are using a scripted label, you must use a specific syntax to display the label. For example, use syntax like the following to add the contents of the
file_namefield to the url:http://example.com/datafiles/@doc[_source][file_name]@. -
Index pattern used by this table: Specify an index pattern that names the Elasticsearch indices that are used by this entity table. You can update the index pattern to change its associated index or even to select multiple indices.
To specify multiple indices, you can add either an asterisk (
*) or a comma (,). For example, the patternmyindex-*matches all indices with names that start withmyindex-, such asmyindex,myindex-1, andmyindex-2. The patternmyindex-1,myindex-2includesmyindex-1andmyindex-2, but notmyindex.Changing this setting will impact this entity table, the searches derived from it, and all of the associated dashboards and visualizations.
-
Time filter: Select Enable the Time filter based on the following field if you want the entity table to be filterable by time. In the dropdown list that appears, specify a valid time field from the underlying Elasticsearch index.
The Fields tab
You can use the search field to search for specific fields in the entity table that you want to inspect or configure.
You can switch between Fingerprint view and Standard view: Fingerprint view displays some additional information about fields, such as samples, the number of non-null values, date range, and so on.
The fields are read-only, but can be modified by clicking Edit Mode.
In edit mode, you can add, rename, and delete fields.
|
If the number of records in the entity table exceeds 10,000, then editing fields is restricted because it would require a re-indexing of the index. If you need to increase the threshold of the entity table, go to Management → Advanced Settings and modify the |
You can also activate the following options:
-
Unique value: Select the check box on fields that contain unique values in each record. For example, if your data contains an ID field, the value of the ID can help to identify that record in the UI.
-
Single value: Select the check box on fields that contain no more than one value.
-
Format: Allows you to control the way that specific values are displayed. It can also cause values to be completely changed and prevent highlighting in Discover from working. The following options are available:
-
Boolean
-
color
-
string (default)
-
truncated string
-
URL
-
The following information is available in columns for each of the fields:
-
Searchable: Indicates that the field can be searched by using the search bar or the global search interface.
-
Aggregatable: Indicates that the field can be used in aggregations in visualizations.
-
Excluded: Indicates that the field is excluded from
_sourcewhen it is fetched. -
Popularity: Modify this value to change the order in which record contents are displayed.
|
If your index is based on a star pattern or is a multi-index, you cannot add, rename, or delete fields. |
You can sort the fields by clicking their column header. And you can switch to ascending or descending order by clicking the arrow that appears in the column header that you sort by.
Refresh the field table by clicking Refresh field list.
The Data tab
From the Data tab, you can explore the data in the entity table, which can be useful after the data is first imported.
You can also perform the following actions:
-
Generate dashboards for the entity table. For more information, see Auto-generating dashboards.
-
Create a search. For more information, see Creating searches.
-
Create a record. If record editing is enabled, you can create new records in the entity table. For more information, see Setting up record editing.
-
Perform a bulk import of data from a spreadsheet or a datasource.
The Relations tab
The Relations tab allows you to define relations between entities.
For more information, see Adding relations between entities.
The Scripted fields tab
Scripted fields are computed in real time from your data. They can be used in visualizations and displayed in your records. However, they cannot be searched.
Before you use scripted fields, see the Elasticsearch documentation about script fields and scripts in aggregations.
|
Scripted fields can be used to display and aggregate calculated values. For this reason, they can be very slow and, if configured incorrectly, they can cause Siren Investigate to become unusable. There is no protection from unexpected exceptions that are caused by script errors. |
Scripted fields use the languages that are enabled in the back-end system. By default, the language that is used is the Painless Elasticsearch language.
|
Ensure that you access the version of Elasticsearch documentation that matches the back-end version that you are using. |
To access values in the document, use the following format:
doc['some_field'].value
Painless is powerful and easy to use. It provides access to many native Java APIs and has an easy-to-learn syntax.
|
Currently, Siren Investigate does not support named functions in Painless scripts. Alternatively, you can use Lucene Expressions. These are a lot like JavaScript, but limited to basic arithmetic, bitwise and comparison operations. |
Lucene Expressions have the following limitations:
-
Only numeric, boolean, date and geo_point fields may be accessed.
-
Stored fields are not available.
-
If a field is sparse (only some documents contain a value), documents missing the field will have a value of 0.
Arithmetic operators |
+, -, *, /, % |
Bitwise operators |
, &, ^, ~, <<, >>, >>> |
Boolean operators* (including the ternary operator) |
&&, !, ?: |
Comparison operators |
<, ⇐, ==, >=, > |
Common mathematic functions |
abs, ceil, exp, floor, ln, log10, logn, max, min, sqrt, pow |
Trigonometric library functions |
acosh, acos, asinh, asin, atanh, atan, atan2, cosh, cos, sinh, sin, tanh, tan |
Distance functions |
haversin |
Miscellaneous functions |
min, max |
*Another boolean operator that is supported is ||
Scripted fields have the following properties:
-
Name
-
Language:
-
expression
-
painless (default)
-
-
Type:
-
Boolean
-
date
-
number
-
string
-
-
Format: Enables you to control the way that specific values are displayed. It can also cause values to be completely changed and prevent highlighting in Discover from working. The following options are available:
-
Boolean
-
bytes
-
color
-
duration
-
number (default)
-
percentage
-
string
-
URL
-
-
Popularity
-
Unique value
-
Single value
-
Script
Click Create field to save your changes.
The Options tab
On the Options tab, you can take measures to filter data to improve system performance.
Source filters
Source filters can be used to exclude one or more fields when fetching the document source. This happens when viewing a document in the Discover app, or with a table displaying results from a saved search in the Dashboard app.
Each row is built using the source of a single record. If you have records with large or unimportant fields you may benefit from filtering those out at this lower level.
|
Multi-fields will incorrectly appear as matches in the table. These filters only apply to fields in the original source document, so that matching multi-fields are actually not filtered. |
Enter a string in the Source Filter field and click Add. Filters accept wildcards, for example, user* will return fields starting with "user".
Sampling on the graph
In the Graph Browser, you can set a graph expansion limit, which controls how many records can be imported into a graph from a dashboard. This is called sampling.
For more information, see Sampling data in the graph.
Minimizing expensive queries
When using dashboards sometimes removing a filter or setting a broad time range can cause the system to produce queries which are too expensive to process. To prevent this situation, you can set limits on the time range that’s applied, or on the number of records that can be added to a dashboard.
For more information, see Minimizing expensive queries.
Highlighting
Siren Investigate applies Lucene highlighter methods to compute how highlighting is applied to the text.
In the advanced settings, the setting default:highlight-type is available, which is set to UNIFIED by default. The other available highlight type is PLAIN. For more information, see the Elasticsearch documentation.
The Template scripts tab
|
To enable this feature, make sure that scripting is enabled and that the |
The Template scripts tab gives you the ability to register scripted perspectives that can customize the appearance of the Record View panel and define custom columns in a Record Table. Perspectives can also define actions to download reports in any file format.
Perspectives are code snippets registered in a template script. You can define two types of perspectives:
-
View perspectives - used to display interactive data within Siren Investigate.
-
Binary perspectives - used to represent data as a static resource that you can download, view, or open individually from Siren Investigate.
Adding and editing perspectives
To define new perspectives, you must create a new template script by clicking the Create template script button. To edit an existing perspective, click the edit button on a perspective row to open the corresponding script.
To add perspectives to the Record viewer or Table visualization lists:
-
Click the Add perspectives button and select the perspectives to add in the following Add Perspectives modal.
-
Preview the perspective:
-
Click any perspective from the list to preview it on the Template scripts tab.
-
When viewing available perspectives in the Add Perspectives modal, click the play button next to the perspective.
-
Binary perspectives display a checkmark in the download column in the list of perspectives. This indicates that when used in the Overview tab or Record Table, you can download the record data made available by that perspective.
Creating the template script and perspectives registration
|
Version 1 of Template scripts is deprecated. This documentation covers and explains the usage of version 2 of the Templates scripts. If you need instructions on how to create templates with version 1 see templating and reporting. |
See the following example showing the basics of how to create a template script and register the perspectives:
const loading = 'Loading...';
function setInitialData() {
return ({ companyName: 'Loading...' });
}
function valueString(value) {
switch (value) {
case undefined: return <i>{loading}</i>;
case null: return <i>No data</i>;
default: return value;
}
}
function currencyString(value) {
switch (value) {
case undefined: return <i>{loading}</i>;
case null: return <i>No data</i>;
case 0: return <i>No investments</i>;
default: return `${value} $`;
}
}
/**
* Asynchronous data fetching function to update any data properties required for the rendering of the data.
* "computedData" is a special property available on "input" and shared between "enrich" or "render" to keep the data for the rendering.
* While "enrich" operation is in progress, "render" is called periodically to render the data with its the most recent state.
* When "enrich" is finished, "render" is called with the finalized "computedData".
*/
async function enrichRecordData(input) {
const { record, dataModelEntity, computedData } = input;
const rootEntity = await dataModelEntity.getRoot();
if (await rootEntity.getLabel() !== 'Companies') {
throw new Error('This script only works for Company records');
}
const companyName = await record.getLabel();
computedData.companyName = companyName;
const securedInvestmentsRelation = (await sirenapi.Relation.getRelationsByLabel('secured'))[0];
const investments = await record.getLinkedRecords(securedInvestmentsRelation, {
size: 1000,
orderBy: { field: 'raised_amount', order: 'desc' }
});
let raisedAmount = 0;
for (const investment of investments) {
const amount = (await investment.getFirstRawFieldValue('raised_amount')) || 0;
raisedAmount += amount;
}
computedData.raisedAmount = raisedAmount;
}
/**
* The function to render and present data which returns "JSX.Element".
* Additionally to all properties available in "input", it has access to "computedData"
* processed by "enrich" (if this operation defined on the script and is taking the place).
*/
function renderRecordData(input) {
const { computedData } = input;
return (
<EuiText>
<h1>
<EuiTextColor color="success"><EuiIcon type="cheer" />{computedData.companyName}</EuiTextColor>
</h1>
<p>Total raised amount: {currencyString(input.computedData.raisedAmount)}</p>
</EuiText>
);
}
/**
* The function to render the data as a binary output and has no strict requirements about output.
* This example shows how to invoke Reporting API to render data as "pdf" and download it.
* Additionally to all properties available in "input", it has access to "computedData"
* processed by "enrich" (if this operation defined on the script and is taking the place).
*/
function downloadRecordData() {
return async function (input) {
const { computedData } = input;
// The identifier of the PDF template
const pdfTemplateId = 'r10S7Ky7Y';
sirenapi.Reporting.download(pdfTemplateId, computedData, `${recordData.computedData}.pdf`);
}
}
/**
* "registerPerspectives()" is called to register the "perspectives".
* The "view" and "binary" objects list the type-specific which should be registered by the script.
*
* Each perspective has following structure:
* - "initalData" is an optional property used to set the initial data prior to any data processing taking place.
* - "enrich" is an optional property used to fetch and update data which will be used in the view / download.
* - "render" is a function which either renders the record view output or initialises the download.
*/
context.registerPerspectives({
view: {
record: {
initialData: setInitialData,
enrich: enrichRecordData,
render: renderRecordData
},
cell: {
initialData: setInitialData,
enrich: enrichRecordData,
render: renderRecordData
}
},
binary: {
pdf: {
initialData: setInitialData,
enrich: enrichRecordData,
render: downloadRecordData
}
}
});For step-by-step instructions on how to create templates and downloadable reports see templating and reporting. These tutorials describe creation of the perspectives which you can use on the Record View and the Record Table.
For more information about script editing, see Templates API and Creating scripts.
The Editing tab
The settings on the Editing tab allow you to configure how changes made to a record of an entity table should be handled.
For more information, see Setting up record editing.
The Searching tab
The Searching tab contains settings that you can use to control the results that appear in the Global Search interface.
To enable searching on the entity table, select the checkbox labeled The <name> entity table is available in searches. Only entity tables that are enabled for searching will appear in the Search in dropdown menu of the Global Search and in Global Search results.
You can set the Boost search value of an entity table to prioritize its appearance in search results over other entity tables. The boost value multiplies the search scores of all records of the entity table, making them more likely to appear first in search results.
|
The boost value of an entity table is actually applied on the associated Elasticsearch indices. In situations where an index is included in multiple entity tables, the boost level will be taken from the entity table with the greater value. For example, if one entity table has an index pattern |
You can enable or disable and set the boost value for individual fields in the Field settings section. To enable or disable fields for searching, select the check boxes under the Searchable field column. To change field boost values, edit the text boxes in the Search boost column.
|
When running queries, Elasticsearch does not provide a way to differentiate between fields with the same name in different indices. As a consequence, if you have the same field in two separate entity tables, then it will be considered "enabled" for searching when it is enabled in at least one of the entity tables. Similarly, the applied boost value will be the maximum boost value among all entity tables where it is enabled for searching. |
The Data model graph
On the Data model graph tab, you can visualize the connected data in a graph to see how the entities relate to one another.
The graph gives a visual representation of the relations (the connections between entities) that are configured on the Relations tab.
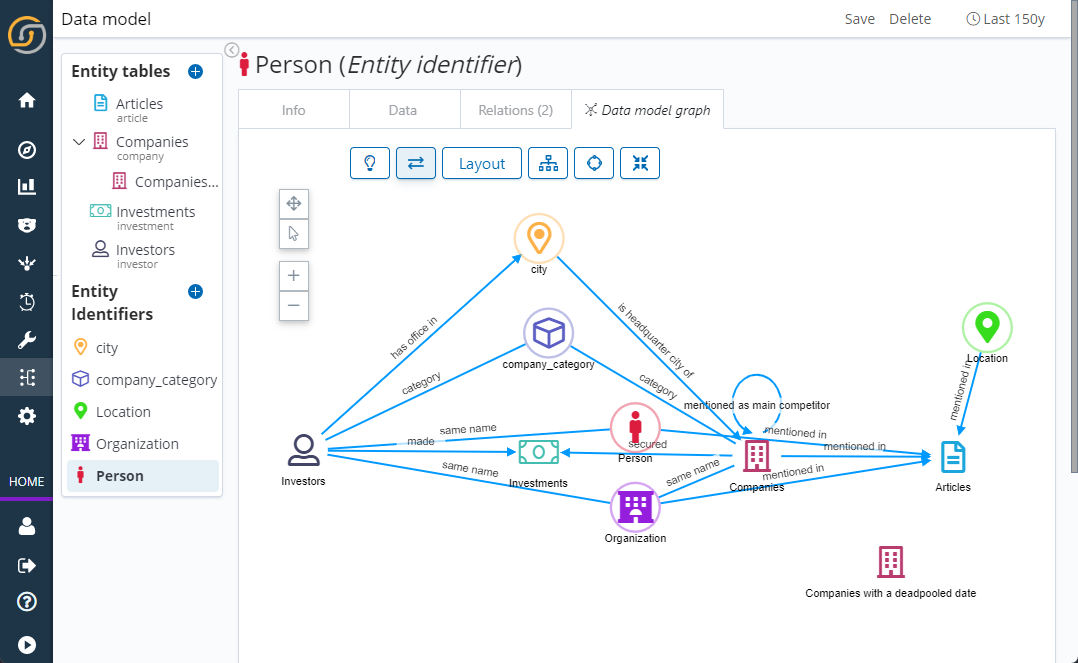
Deleting entity tables
To delete an entity table, select the entity table in the list and click Delete in the Options menu.
Select one of following options:
-
Remove entity table object only: Removes the entity table from the data model and retains the data in the index.
-
Delete data only: Deletes the data from the index and retains the entity table object in the data model.
-
Delete all: Deletes the data from the index, deletes the index, and removes the entity table object from the data model.
|
The last two options are available only if the index is based on a single index or an index that is not a star pattern. If you select either of these options, you must confirm your selection by typing the word |
Refreshing the index fields list
When you add an index mapping, Siren Investigate automatically scans the indices that match the pattern to display a list of the index fields.
You can refresh the index fields list to pick up any newly-added fields.
Refreshing the index fields list also resets Siren Investigate’s popularity counters for the fields.
The popularity counters keep track of the fields you have used most often within Siren Investigate and are used to sort fields within lists.
To refresh the index fields list, go to the Fields tab and click Refresh field list.